NewWave Intelligent Business
Systems, NIBS Inc.

NewWave Intelligent Business
Systems, NIBS Inc.
Neural Network Computing
The Sudden Rise of Neurocomputing
The majority of information processing today is carried out by digital computers. This has led to the widely held misperception that information processing is dependent on digital computers. However, if we look at cybernetics and the other disciplines that form the basis of information science, we see that information processing originates with living creatures in their struggle to survive in their environments, and that the information being processed by computers today accounts for only a small part - the automated portion - of this. Viewed in this light, we can begin to consider the possibility of information processing devices that differ from conventional computers. In fact, research aimed at realizing a variety of different types of information processing devices is already being carried out, albeit in the shadows of the major successes achieved in the realm of digital computers. One direction that this research is taking is toward the development of an information processing device that mimics the structures and operating principles found in the information processing systems possessed by humans and other living creatures.
Digital computers developed rapidly in and after the late 1940's, and after originally being applied to the field of mathematical computations, have found expanded applications in a variety of areas, to include text (word), symbol, image and voice processing, i.e. pattern information processing, robot control and artificial intelligence. However, the fundamental structure of digital computers is based on the principle of sequential (serial) processing, which has little if anything in common with the human nervous system.
The human nervous system, it is now known, consists of an extremely large number of nerve cells, or neurons, which operate in parallel to process various types of information. By taking a hint from the structure of the human nervous system, we should be able to build a new type of advanced parallel information processing device.
In addition to the increasingly large volumes of data that we must process as a result of recent developments in sensor technology and the progress of information technology, there is also a growing requirement to simultaneously gather and process huge amounts of data from multiple sensors and other sources. This situation is creating a need in various fields to switch from conventional computers that process information sequentially, to parallel computers equipped with multiple processing elements aligned to operate in parallel to process information.
Besides the social requirements just cited, a number of other factors have been at work during the 1980's to prompt research on new forms of information processing devices. For instance, recent neurophysiological experiments have shed considerable light on the structure of the brain, and even in fields such as cognitive science, which study human information processing processes at the macro level, we are beginning to see proposals for models that call for multiple processing elements aligned to operate in parallel. Research in the fields of mathematical science and physics is also concentrating more on the mathematical analysis of systems comprising multiple elements that interact in complex ways. These factors gave birth to a major research trend aimed at clarifying the structures and operating principles inherent in the information processing systems of human beings and other animals, and constructing an information processing device based on these structures and operating principles. The term "neurocomputing" is the name used to refer to the information engineering aspects of this research.
The Biological Foundation of NeuroComputing
Neurocomputing involves processing information by means of changing the states of networks formed by interconnecting extremely large numbers of simple processing elements, which interact with one another by exchanging signals. Networks such as the one just described are called artificial neural networks (ANNs), in the sense that they represent simplified models of natural nerve or neural networks.
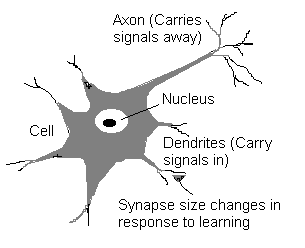
Fig. 1. A simple neuron cell

Fig. 2. A schematic diagram of a neuron
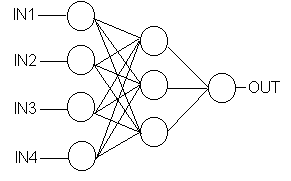
Fig. 3. A feed forward neural network
The basic processing element in the nervous system is the neuron. The human brain is composed of about 1011 of over 100 types. Tree-like networks of nerve fiber called dendrites are connected to the cell body or soma, where the cell nucleus is located. Extending from the cell body is a single long fiber called the axon, which eventually branches into strands and substrands, and are connected to other neurons through synaptic junctions, or synapses.
The transmission of signals from one neuron to another at a synapses is a complex chemical process in which specific transmitter substances are released from the sending end of the junction. The effect is to raise to lower the electrical potential inside the body of the receiving cell. If the potential reaches a threshold, a pulse is sent down the axon - we then say the cell has "fired".
In a simplified mathematical model of the neuron, the effects of the synapses are represented by "weights" which modulates the effect of the associated input signals, and the nonlinear characteristics exhibited by neurons is represented by a transfer function which is usually the sigmoid function. The neuron impulse is then computed as the weighted sum of the input signals, transformed by the transfer function. The learning capability of an artificial neuron is achieved by adjusting the weights in accordance to the chosen learning algorithm, usually by a small amount *Wj = **Xj where * is called the learning rate and * the momentum rate.
Building A Neural Network
Since 1958, when psychologist Frank Rosenblatt proposed the "Perceptron," a pattern recognition device with learning capabilities, the hierarchical neural network has been the most widely studied form of network structure. A hierarchical neural network is one that links multiple neurons together hierarchically, as shown in Figure 3. The special characteristic of this type of network is its simple dynamics. That is, when a signal is input into the input layer, it is propagated to the next layer by the interconnections between the neurons. Simple processing is performed on this signal by the neurons of the receiving layer prior to its being propagated on to the next layer. This process is repeated until the signal reaches the output layer completing the processing process for that signal.
The manner in which the various neurons in the intermediary (hidden) layers process the input signal will determine the kind of output signal it becomes (how it is transformed). As you can see, then, hierarchical network dynamics are determined by the weight and threshold parameters of each of their units. If input signals can be transformed to the proper output signals by adjusting these values (parameters), then hierarchical networks can be used effectively to perform information processing.
Since it is difficult to accurately determine multiple parameter values, a learning method is employed. This involves creating a network that randomly determines parameter values. This network is then used to carry out input-to-output transformations for actual problems. The correct final parameters are obtained by properly modifying the parameters in accordance with the errors that the network makes in the process. Quite a few such learning methods have been proposed. Probably the most representative of these is the error back-propagation learning method proposed by D. E. Rumelhart et al. in 1986. This learning method has played a major role in the recent neurocomputing boom.
The back-propagation paradigm has been tested in numerous applications including bond rating, mortgage application evaluation, protein structure determination, backgammon playing, and handwritten digit recognition. Choosing the right methodology, or backpropagation algorithm, is another important consideration. In working with the financial applications, many have found that the back-propagation algorithm can be very slow. Without using advanced learning techniques to speed the process up, it is hard to effectively apply backpropagation to real-world problems. Overfitting of a neural network model is another area which can cause beginners difficulty. Overfitting happens when an ANN model is trained on one set of data, and it learns that data too well. This may cause the model to have poor generalization abilities - the model may instead give quite poor results for other sets of data.
For an in-depth coverage of other neural network models and their learning algorithms, please refer to the Technical Reading at the end of this User's Guide, the Technical Reference (sold separately), those papers listed in the Reference, or any other reference books on neural networks and relevant technology.
Some Real-World Applications
ANNs can be regarded, in one respect, as multivariate nonlinear analytical tools, and are known to be very good at recognizing patterns from noisy, complex data, and estimating their nonlinear relationships. Many studies have shown that ANNs have the capability to learn the underlying mechanics of the time series, or, in the case of trading applications, the market dynamics. In general, ANNs are known to possess these capabilities:
A number of development projects involving ANN technology have been publicized in the media recently. For example, Nippon Steel Corp. has built a blast furnace operation control support system that makes use of ANNs. The neural network employed in this system has been equipped with functions that enable it to learn the relationship between sensor data and the eight kinds of temperature distribution patterns known from experience to pertain to the overall operation of blast furnaces, and to instantaneously recognize and output that pattern which most closely approximates sensor data input into the system. The neural network learns very quickly, and achieves a better than 90% pattern recognition ratio following learning. Since this system has been performing extremely well during operational testing, Nippon Steel is planning to introduce it into other aspects of its operations in addition to blast furnace control, to include the diagnosis of malfunctions, and other control processes.
A second example is the experimental work started by Daiwa Securities Co., Ltd. and NEC Corporation on applying neural network technology to the learning and recognition of stock price chart patterns for use in stock price forecasting. NEC had already developed neural network simulation software for use on its EWS 4800 series of workstations, and, by limiting stock price chart pattern learning to a few dozen major stocks, has improved the accuracy of this software's forecasting capabilities. Based on these results, the Daiwa Computer Services Co., Ltd., an information processing subsidiary of the Daiwa Securities Group, transferred the NEC system to its supercomputer and taught it to recognize the stock price chart patterns for 1,134 companies listed on the Tokyo Stock Exchange. DCS has since been putting this system to good use in the performance of stock price forecasting.
Mitsubishi Electric has combined neural network technology with optical technology to achieve the world's first basic optical neurocomputer system capable of recognizing the 26 letters of the alphabet. The system comprises a set of light-emitting diodes (LED) that output letter patterns as optical signals, optical fibers, liquid crystal displays (LCD) that display letter patterns and light receiving devices that read these letters. When letter data is input into this system, light emitted from the LEDs is input to the light receiving devices through the LCDs. At that time, the light receiving devices that receive the light, as well as the strength of the light they receive, is determined by the manner in which that light passes through the LCDs. The letter in question is delineated by the light receiving devices that receive the strongest light. This system is capable of 100% letter recognition even when slightly misshapen handwritten letters are input.
A fourth example is a development project for a facilities diagnosis system that employs a neural network system commenced by the Nippon Oil Co., Ltd. in cooperation with CSK Research Institute. This project is attracting considerable attention as it is the first time research has been carried out on applying neural network systems to facilities diagnosis. Initially, the project will be aimed at developing a diagnosis system for pump facilities that employs vibration analysis. Nippon Oil operates a total of 1,500 pumps at its Negishi Oil Refinery in Yokohama, Kanagawa Prefecture alone, and must retain large numbers of experienced personnel to maintain these pumps. The company decided to apply neural network technology to pump facilities diagnosis operations with the ultimate goal of saving labor in mind.
Bond rating is another successful ANN application. Bond rating refers to the process by which a particular bond is assigned a label that categorizes the ability of the bond's issuer to repay the coupon and par value of that bond. Thus, for example, the Standard and Poor's organization might assign a rating varying from AAA (very high probability of payment) to BBB (possibility of default in times of economic adversity) for investment grade bonds. The problem here is that there is no hard and fast rule for determining these ratings. Rating agencies must consider a vast spectrum of factors before assigning a rating to an issuer. Some of these factors, such as sales, assets, liabilities, and the like, might be well defined. Others such as willingness to repay are quite nebulous. Thus a precise problem definition is not possible. Dutta (1988) maintains that problems with non conservative domains (the class of problem domains that lack a domain model) such as that seen in the bond-rating problem could be better solved by training a network using back-propagation than by trying to perform a statistical regression. The latter is inappropriate because it is unclear what factors the regression should be performed with, that is, it is not clear what factors the dependent variable (the default risk) really depends on. They describe details of experiments that they conducted with networks having no hidden layers and with networks with one hidden layer (with different numbers of nodes in the hidden layer). Bond ratings for 30 companies together with ten financial variables were used as data in the training of the neural network using back-propagation. The network was then used to predict the ratings of seventeen other issuers and consistently outperformed standard statistical regression techniques.
The Adaptive Decision Systems (ADS) founded by Murray Smith to apply the advances in neural network technology to an area that he knows well, the financial world. Smith earned an MBA from Harvard before working with a financial service corporation for eighteen years. After he saw the potential for using new technology to solve common financial problems such as credit scoring or evaluation, he decided to start ADS. Smith sees ADS's mission as having three principle components:
ADS is using its expertise in two areas: credit scoring and target marketing. This type of credit scoring is used to screen applicants for credit cards, based on known facts about the individuals applying. These facts usually include such things as salary, number of checking accounts, and previous credit history. Large banks and other lenders lose millions each year from bad debts. Even a small increase in the ability to predict accurately which accounts will go unpaid can result in hundreds of thousands of dollars saved each year for large lenders. To help fight this problem, major banks and finance companies are actively pursuing new technologies and systems that can aid in credit prediction.
Using the techniques outlined above, ADS has been successful in using ANNs to predict credit account futures. The average ADS credit prediction models performance gains over standard statistical methods are 5%. Even this small increase in ability to predict a credit account's future performance means a large savings for credit grantors. In little over two years, ADS has provided neural network predictive models to four major clients, who for contractual reasons cannot be named. Of these clients, one is using an ADS model for credit scoring in its standard system, while the other three are further refining and integrating the process.
ADS has also applied neural network techniques to the field of marketing. For years, advertising agencies and other companies have been trying to identify and sell to target, or specific, markets. For example, a company selling life insurance might send out an advertisement enclosed in a monthly credit card bill. What the company would like to be able to do is to send out a small percentage of these advertisements to consumers, and keep information on what type of person responds. Once the company has data on who responded, it can then built a predictive model to analyze potentially good customers. Thus, a life insurance company may be able to save money by only sending out advertisements to a select 1 million credit card holders who are more likely to buy life insurance, rather than to all credit card holders. Successful target marketing can save large companies hundreds of thousands of dollars each year.
ADS provides consulting services to large credit financial services companies. According to Smith, the majority of this work has been in developing and testing neural network models for data sets supplied by the companies. These firms provide ADS with raw data from the applications department. For example, a typical data set might have 40,000 records, with each record having between 30 and 100 different data fields. These fields contain data such as the credit card holder's age, occupation, salary, phone number, and past payment history. It may also include information obtained from credit bureaus, such as the number of other charge accounts, the number of times the applicant has applied for credit recently, and the existence of prior bankruptcies.
Each record also has a data field that specifies whether the account is good or bad, that is, whether that account was written off as a bad debt or not. For example, a data set may have information on past payment histories (ie: a one year payment history with the number of 1, 2, and 3 month delinquencies) and a good or bad score based on whether the account was delinquent after 5 months.
All of this data is processed and used to build a predictive applicant credit scoring model. In building a model, the typical data set provided by the financial institution travels through four steps: reading, analyzing, building a model, and implementation.
The first step in the ADS process is reading the raw data set into a PC. This data is generally in an ASCII (text) format, and is pre-processed to yield a more compact and faster-access binary format. In addition, during the creation of the binary data file, data fields that are obviously not needed or helpful for credit prediction are discarded. An example of such a field would be the credit card holder's phone number, or the credit card holder's birth date when the age is already given. Once the raw data is read into a compact binary data file, predictive variables have to be found.
The second step in ADS's process is to use the pre-processed data file and specially designed data analysis programs to determine which data fields are predictive of the actual result of each record. It is important that the inputs to the backpropagation network be at least somewhat predictive. Data fields that have little predictability will only add extra degrees of freedom to network, and can contribute to the network overfitting the training set.
This happens when the network learns the training set so well that it loses one of neural networks greatest strengths - its ability to generalize. For example, by using these special programs, ADS may see that the age of a credit card holder is predictive of the account delinquency. They might see that 18-25 year old tend to default more often than 55-80 year old. If so, the most predictive categories for each record type are stored for later processing. In this example, the age record may be broken down into three categories: 18-25, 26-55, and 56-80. Analysis may show that some records, such as spouse's length of time at job, are not predictive at all, and they are noted for later deletion. For each data set, all the variables (age, occupation, payment histories, etc.,) are run through these decision programs to determine their predictability. If a variable is predictive, it is broken down into different categories (typically 1-10) for processing by the neural network.
ADS then takes the processed data and the associated categories and develops a backpropagation neural network predictive model for the data set. The backpropagation network uses the delta-bar-delta rule. the input nodes for the backpropagation network are determined by the categories that the deciding step has yielded. Thus a typical application might have approximately 100 input nodes for 40 different data fields. Some fields may merely have a single node, such as whether the applicant has declared bankruptcy, while others, such as the card holder's age, may have as many as 5. The data set is fed through the network, and a predetermined set is held back for testing, typically 25% of the original data set. Training and testing sets of data are run alternatively to measure the error as training progresses. When optimal error reduction is reached, training is halted, and the network weights and configuration are saved.
Once ADS has developed a predictive neural network model for a data set, the customers can then use the neural network in a feed forward, non-learning mode to judge applications credit risks. The network can be implemented on their mainframes as a function call in their applications processing system.
A statistical-based hybrid neural network at Chase Manhattan Bank is one of the largest and most successful AI applications in the United States. It addresses a critical success factor in the bank's strategic plan: reducing losses on loans made to public and private corporations. Most of Chase's business for corporations involves assessing their creditworthiness. Chase loans $300 million annually and has long searched for tools to improve loan assessment. This assessment allows Chase to mitigate risk and seek out new business opportunities. Financial-restructuring deals are promising business opportunities for the bank.
In 1985 Chase began a search for new quantitative techniques to assist senior loan officers in forecasting the creditworthiness of corporate loan candidates. Chase located Inductive Inference Inc. (headed by Dr. David Rothenberg), a New York City company with a history of successfully applying neural-network technology to statistical pattern analysis. A test model was built, evaluated, and independently audited. The results were reviewed by the Chase CEO committee in 1987 and Inductive Inference was granted a multimillion dollar contract. Consequently, Chase established a 36-member internal consulting organization called Chase Financial Technologies to oversee the development of pattern-analysis network models for evaluating corporate loan risk.
The resulting models, called the Creditview system, perform three-year forecasts that indicate the likelihood of a company being assigned a Chase risk classification of good, criticized, or charged-off. In addition to the overall forecast, Creditview provides a detailed listing of the items that significantly contributed to the forecast, an expert-system-generated interpretation of those items, and several comparison reports. Creditview models run on a Chase Financial Technologies host computer. A user system resides at each user's PC and communicates with the host through telephone lines. In addition, conventional financial statement analysis may be performed using Chase's Financial Reporting System, an independent financial spreading and analysis package designed for conventional financial statement analysis. The Financial Reporting System also resides on the user's PC and permits a company's standard financial statements to be accessed and displayed. System data is obtained from COMPUSTAT.
It took 15 years for Inductive Inference to develop ADAM, a tool that generates the models such as those used in Creditview. ADAM is a statistically based technique that extracts a collection of Boolean formulae from historical data and captures rules most significant in determining the obligor's creditworthiness. ADAM identifies rules and their combinations that, based on historical data, may be expected to do three-year forecasts reliably. The historical data is also used to embed the Boolean formulae in a network that evaluates the significance of each possible formulae combination that may be satisfied by a particular company.
ADAM's pattern-analysis technology provides the ability to construct a hybrid neural network, if enough high-quality historical data is available. Each hybrid net represents a separate "model" produced by ADAM. The PCLM (Public Loan Company model), the first model implemented at Chase, derives from Chase's extensive loan history of large, publicly traded companies and their past financial data. (Chase has both publicly and privately owned corporations in its base of clients and prospects. Separate credit-risk forecasting models will be developed for public and private companies because their particular characteristics will probably mandate separate assessments and analysis by the bank.). The input to ADAM includes: (1) Historical financial-statement data on good and bad obligors (the learning sample), (2) Industry norms calculated using financial-statement data from companies in specific industries.
These norms reflect industry characteristics. The historical data analyzed by ADAM to produce forecasting models consists of a large collection of data units. Each data unit contains as much as six years of consecutive financial data for a particular company, corresponding industry norms, and the company's status three years after the last year of data. (The last of the six years is called the "year of the data unit.") The data unit's status is the company's rating - G stands for good, C stands for criticized, and X stands for charged-off. ADAM uses this data to construct a large set (say, a thousand) of candidate variables that may or may not indicate a company's future financial condition. These variables are used to form patterns.
A pattern is fundamentally a statement about the
value of a particular financial variable or set of variables. A very simple
pattern may have the form: C1< V1 < C2 or V1 < C1, where V1 is
a financial variable and C1 and C2 are constants. For example: 1.75<
QuickRatio < 2.00 could be a simple pattern. Typically, patterns are
more complex; they have several elements of this kind and are combined
by using and, or, and not. This example could be one of a small complex
pattern:
C1 < V1 < C2
V2 < C3
C4 < V3 < C5 .and. C6 < V4 < C7
C8 < V5 < C9
where all the C's are constants and V's financial variables. Candidate variables are arranged into thousands of complex patterns and analyzed by ADAM to produce an optimal set of variables and patterns that form a pattern network called the Forecaster. The criteria for selection of patterns are:
Score: The score (as observed in the historical data) measures the ability of the pattern to differentiate between the categories good, criticized, and charged-off; in other words, the ability of the pattern to classify correctly.
Complexity: Complexity is a measure of how complicated the pattern is (in terms of number of variables), simple patterns within it, and the amount of historical data it satisfies.
Spuriousness: A measure of the likelihood that the pattern's score (how well it predicts) is due solely to chance.
These statistics are used to evaluate the predictive power of the patterns and ensure that whatever predictive power is uncovered is not by chance. To each pattern and status a probability (called the "precision") exists that a data unit corresponding to the pattern will have that status. ADAM uses a proprietary network-balancing technique that selects the patterns for the network to maximize precision and minimize bias.
ADAM was used to develop the PCLM, an expert system based on historical data that can predict the likelihood of a public firm being rated good, criticized, or charged-off three years in advance. The PCLM comprises two parts: the Forecaster built by the ADAM technology from large publicly traded companies (residing on a Chase host computer), and a PC-based user system that allows access to the model on the host computer to generate forecasts for particular companies, perform various analyses, and print reports. Note that information about an obligor's specific credit facility (whether the facility is secured, covenants, and so on) is not considered by the PCLM. The system evaluates the company itself rather than the risk of its defaulting in specific credit payments.
The PCLM produces these reports: Contributing Variables, Expert-System Interpretation, Two-Year Comparison: Items of Increased Significance, Two-Year Comparison: Items of Decreased Significance, and Two-Year Comparison: Items That Changed Risk Category. Of these reports, Contributing Variables contains PCLM's primary output; the others derive from the data contained in it. Contributing Variables comprises an overall forecast for the company in question along with a list of the variables that most strongly contributed to the forecast. The basic report consists of these sections:
Section 1: General information. Contains the company name, forecast year, standard industrial code (SIC), data source, date, and years of data that were used in generating the forecast.
Section 2: Industry peer group. Defines the industry peer group as determined by the model for the company. The company's asset size and geographic location are shown in this section. Information on the industry peer group consists of its SIC, the latest year for which industry norms were calculated, the number of firms in the peer group, and the peer-group reference number (useful in determining the peer group's members).
Section 3: Overall forecast. Shows the forecast rating for the company (G, C, or X). These ratings are mathematically combined into a single "vulnerability index" that helps compare the relative risk among different forecasts (different companies or years for the same company). In addition, to assist the analyst in evaluating the forecast's significance, the company's forecast compared to others in Chase's experience is shown in several ways. Chase Rank shows the relative percentile of this company's good rating compared to all Chase obligors in the years 1986-1988 (for example, if the company's Chase Rank was 25%, for all Chase obligors from 1986-1988, 75% have a higher and 25% have a lower rating for good), and Percent Going to Criticized and Charged-off shows the historical outcome of similarly ranked companies.
Section 4: A list of contributing variables most strongly influencing the forecast. These variables are organized into categories and by contributions to strength and weakness within each category: profitability, asset efficiency, cash flow, capital structure and liquidity; and market.
Section 5: A list of contributing variables compared to the best or worst quartile of companies in the industry (defined as its peer group) that most strongly influence the forecast.
PCLM benefits the user because it identifies the strengths and vulnerabilities in the financial structure of the obligor and forecasts the impact of these factors on the firm's financial health three years into the future. Chase tested the system extensively and, having identified many potentially troublesome loans.
Many recent studies and success stories have been
reported in various international conferences (eg. International Joint
Conference on Neural Networks, World Congress on Neural Networks, IEEE
World Congress on Computational Intelligence) and journals and magazines
(eg. IEEE Expert Systems, AI in Finance, AI Experts, Technical Analysis
of Stocks & Commodities, PC AI). A number of real applications can
also be found in the NeuroForecaster package. Based on these successful
applications, it is therefore evident that the neural network technology
can be applied to many real-world problems especially those related to
business, financial and engineering modeling.
![]()
Standard Disclaimer:
By visiting these pages you expressly
agree that neither NIBS nor anyone else involved in creating, producing
or delivering the information and products shall be liable for any damages
arising out of use of these pages.
Copyright © 1993-97, NIBS Pte Ltd, all rights reserved world-wide.